-
15 though early morning of 16 April
Date: 04/16/16 Keywords: no keywords
As NR would say...
Now you know what I know
WS Campbell, Inspector
Duty Officer
OPD
TDY/ NYD OIG FR -
15 though early morning of 16 April
Date: 04/16/16 Keywords: no keywords
As NR would say...
Now you know what I know
WS Campbell, Inspector
Duty Officer
OPD
TDY/ NYD OIG FR -
Divide a circle
Date: 05/11/11 Keywords: programming
Hi!
I've been member of this community for quite time, and now I need some advise.
Question is how do I devide given circle with radius R into N vertical segments with same area?
And by vertical I mean that devising lines should be parralell to the diametr line of that circle. One more thing - N is always even. Simple example is N = 2 : and we have circle divided vertically into two parts of equal area with deametr line.
I need this to speedup my litlle research on mathematical statistics with parallel GPU eval.
Any help In form of formula, or ref to the known algorithm (if it does exists) or some code on almost any programming language would be g8.
UPD
Illustration added. Case: R=1 N=6, areas of all segments are equal.
I need to know OX points marked with question marks.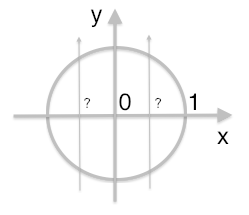
-
Divide a circle
Date: 05/11/11 Keywords: programming
Hi!
I've been member of this community for quite time, and now I need some advise.
Question is how do I devide given circle with radius R into N vertical segments with same area?
And by vertical I mean that devising lines should be parralell to the diametr line of that circle. One more thing - N is always even. Simple example is N = 2 : and we have circle divided vertically into two parts of equal area with deametr line.
I need this to speedup my litlle research on mathematical statistics with parallel GPU eval.
Any help In form of formula, or ref to the known algorithm (if it does exists) or some code on almost any programming language would be g8.
UPD
Illustration added. Case: R=1 N=6, areas of all segments are equal.
I need to know OX points marked with question marks.
-
Contributing without even knowing
Date: 08/06/10 Keywords: software, web
Flash animations on webpages consume a surprisingly large amount of CPU time, especially if you keep many pages open at once. When you think about it, this is a very fast and efficient way to distribute some software onto a lot of computers. Put up a banner on a major news site and you have your code ticking along on thousands of computers within minutes, and with no user interaction.
It's strange that distributed computing has not leapt onto this. Granted, it's a narrow nieche, with the program running only for a few minutes and with a limited size, but there are still plenty of cases where it could work. I've only found This proof of concept of distributed flash computing. This example require some user interaction and fills a whole screen, but there seems to be no reason why it couldn't run as a banner ad.
Why isn't this more widespread? -
Contributing without even knowing
Date: 08/06/10 Keywords: software, web
Flash animations on webpages consume a surprisingly large amount of CPU time, especially if you keep many pages open at once. When you think about it, this is a very fast and efficient way to distribute some software onto a lot of computers. Put up a banner on a major news site and you have your code ticking along on thousands of computers within minutes, and with no user interaction.
It's strange that distributed computing has not leapt onto this. Granted, it's a narrow nieche, with the program running only for a few minutes and with a limited size, but there are still plenty of cases where it could work. I've only found This proof of concept of distributed flash computing. This example require some user interaction and fills a whole screen, but there seems to be no reason why it couldn't run as a banner ad.
Why isn't this more widespread? -
keystream
Date: 05/07/10 Keywords: web
Dear lazy web,
Do you know if there exists any keystream algorithms where in which, given an input key, you can request from the algorithm something like "give me slot 433"?
Let me clarify,
so a typical keystream you seed with some key and then are able to request sequential bytes. In my particular application I want to encrypt 8Kbytes xored against a keystream but have it so it can be randomly read and written to. So I guess it would be like a key-block cipher or something like that. I don't fancy re-implementing crypto so I'm wondering if such a technique exists out there. -
keystream
Date: 05/07/10 Keywords: web
Dear lazy web,
Do you know if there exists any keystream algorithms where in which, given an input key, you can request from the algorithm something like "give me slot 433"?
Let me clarify,
so a typical keystream you seed with some key and then are able to request sequential bytes. In my particular application I want to encrypt 8Kbytes xored against a keystream but have it so it can be randomly read and written to. So I guess it would be like a key-block cipher or something like that. I don't fancy re-implementing crypto so I'm wondering if such a technique exists out there. -
Looking for a job. java team lead / system architect
Date: 03/13/10 Keywords: java
Hi!
At the moment I am looking for a job of java team lead / system architect.
CV
http://www.chantingwolf.narod.ru/cv8en.doc
LinkedIN profile
http://www.linkedin.com/in/mykbova
-Mykola -
Looking for a job. java team lead / system architect
Date: 03/13/10 Keywords: java
Hi!
At the moment I am looking for a job of java team lead / system architect.
CV
http://www.chantingwolf.narod.ru/cv8en.doc
LinkedIN profile
http://www.linkedin.com/in/mykbova
-Mykola -
1st Call for Papers: SIGAI Workshop on Emerging Research Trends in AI (ERTAI-2010)
Date: 01/09/10 Keywords: php, asp, java, web, spam
The Special Interest Group on AI (SIGAI) of Computer Society of India (CSI) announces a *workshop* on "Emerging Research Trends in AI". The workshop will be organised and hosted by CDAC Navi Mumbai, India and is meant to encourage quality research in various aspects of AI, among the Indian academia/industry. For details, refer the first call for papers below (in the LJ Cut), and visit http://sigai.cdacmumbai.in and http://sigai.cdacmumbai.in/index.php/ertai-2010
[Cross-posted at mumbai , ai_research and _scientists_ ]
mumbai , ai_research and _scientists_ ]
SIGAI Workshop on Emerging Research Trends in Artificial Intelligence (ERTAI - 2010)
17th April, 2010, C-DAC, Navi Mumbai, India
Supported by Computer Society of India (CSI)
Background
Artificial Intelligence (AI) has always been a research-rich field with a number of challenging and practically significant problems spanning many areas. These include language processing, multi-agent systems, web mining, information retrieval, semantic web, e-learning, optimization problems, pattern recognition, etc. AI, hence, can offer a wide range of challenging problems matching the palate of every academic or professional. However, most colleges and universities do not have experienced AI researchers to work in these areas.
We also observe an increasing interest among the Indian academia to pursue research, usually aimed at PhD. However, lack of guides with rich research experience often makes it hard for new and aspiring research scholars to identify relevant and useful research topics and to get guidance on their approach and direction. A forum where those pursuing research can exchange ideas and seek guidance, and those seeking to get into research can get a feel of current research would be valuable for both groups.
This is the backdrop driving SIGAI to organize a workshop of this nature.
Proposed Structure of Workshop
It will be a one day programme consisting of,
* Invited talks covering current trends, specific challenges, etc. in Artificial Intelligence
* Invited talks on mentoring research scholars on publication, research methodology, etc.
* Presentations by those currently pursuing research in AI area.
We will have a panel of experienced researchers to evaluate and mentor the research presentations.
Call For Papers
For the research presentations, we are now inviting brief research papers of 5-6 pages, outlining the problem being addressed, approach followed vis a vis existing approaches, current status / results, and future plans. A subset will be short-listed for presentation, based on a formal review process. Papers must have significant AI content to be considered for presentation. Relevant topics include (but are not limited to):
Knowledge Representation
Reasoning
Model-Based Learning
Expert Systems
Data Mining
State Space Search
Cognitive Systems
Vision & Perception
Intelligent User Interfaces
Reactive AI
Ambient Intelligence
Artificial Life
Evolutionary Computing
Fuzzy Systems
Uncertainty in AI
Machine Learning
Constraint Satisfaction
Ontologies
Natural Language Processing
Pattern Recognition
Intelligent Agents
Soft Computing
Planning & Scheduling
Neural Networks
Case-Based Reasoning
Target Audience
Target audience will be primarily:
* Faculty members pursuing research involving AI as the base or as a tool for an application.
* Faculty members interested in pursuing research and exploring areas / options.
* Research scholars working for a post graduate degree.
* Students seriously interested in research, specifically on AI.
Important Dates
* Last date for paper submission: 10th March, 2010
* Acceptance intimation: 25th March, 2010
* Camera ready copy due: 5th April, 2010
* Registration details announcement: 1st February, 2010
Instructions
* Presentations must report original work carried out by the authors.
* Presenters would be given a maximum of 30 minutes for their presentation.
* All participants must register for the workshop.
* Presentation may be submitted via: csi.sigai@gmail.com This e- mail address is being protected from spambots. You need JavaScript enabled to view it
ERTAI Secretariat
Centre for Development of Advanced Computing (Formerly NCST)
Raintree Marg, Near Bharati Vidyapeeth, Sector 7, CBD Belapur
Opp. Kharghar Railway Station, Navi Mumbai 400 614, Maharashtra, INDIA
Telephone: +91-22-27565303
Fax: +91-22-27565004 (on request)
Email: csi.sigai@gmail.com
Web: http://sigai.cdacmumbai.in/ -
1st Call for Papers: SIGAI Workshop on Emerging Research Trends in AI (ERTAI-2010)
Date: 01/09/10 Keywords: php, asp, java, web, spam
The Special Interest Group on AI (SIGAI) of Computer Society of India (CSI) announces a *workshop* on "Emerging Research Trends in AI". The workshop will be organised and hosted by CDAC Navi Mumbai, India and is meant to encourage quality research in various aspects of AI, among the Indian academia/industry. For details, refer the first call for papers below (in the LJ Cut), and visit http://sigai.cdacmumbai.in and http://sigai.cdacmumbai.in/index.php/ertai-2010
[Cross-posted at mumbai , ai_research and _scientists_ ]
mumbai , ai_research and _scientists_ ]
SIGAI Workshop on Emerging Research Trends in Artificial Intelligence (ERTAI - 2010)
17th April, 2010, C-DAC, Navi Mumbai, India
Supported by Computer Society of India (CSI)
Background
Artificial Intelligence (AI) has always been a research-rich field with a number of challenging and practically significant problems spanning many areas. These include language processing, multi-agent systems, web mining, information retrieval, semantic web, e-learning, optimization problems, pattern recognition, etc. AI, hence, can offer a wide range of challenging problems matching the palate of every academic or professional. However, most colleges and universities do not have experienced AI researchers to work in these areas.
We also observe an increasing interest among the Indian academia to pursue research, usually aimed at PhD. However, lack of guides with rich research experience often makes it hard for new and aspiring research scholars to identify relevant and useful research topics and to get guidance on their approach and direction. A forum where those pursuing research can exchange ideas and seek guidance, and those seeking to get into research can get a feel of current research would be valuable for both groups.
This is the backdrop driving SIGAI to organize a workshop of this nature.
Proposed Structure of Workshop
It will be a one day programme consisting of,
* Invited talks covering current trends, specific challenges, etc. in Artificial Intelligence
* Invited talks on mentoring research scholars on publication, research methodology, etc.
* Presentations by those currently pursuing research in AI area.
We will have a panel of experienced researchers to evaluate and mentor the research presentations.
Call For Papers
For the research presentations, we are now inviting brief research papers of 5-6 pages, outlining the problem being addressed, approach followed vis a vis existing approaches, current status / results, and future plans. A subset will be short-listed for presentation, based on a formal review process. Papers must have significant AI content to be considered for presentation. Relevant topics include (but are not limited to):
Knowledge Representation
Reasoning
Model-Based Learning
Expert Systems
Data Mining
State Space Search
Cognitive Systems
Vision & Perception
Intelligent User Interfaces
Reactive AI
Ambient Intelligence
Artificial Life
Evolutionary Computing
Fuzzy Systems
Uncertainty in AI
Machine Learning
Constraint Satisfaction
Ontologies
Natural Language Processing
Pattern Recognition
Intelligent Agents
Soft Computing
Planning & Scheduling
Neural Networks
Case-Based Reasoning
Target Audience
Target audience will be primarily:
* Faculty members pursuing research involving AI as the base or as a tool for an application.
* Faculty members interested in pursuing research and exploring areas / options.
* Research scholars working for a post graduate degree.
* Students seriously interested in research, specifically on AI.
Important Dates
* Last date for paper submission: 10th March, 2010
* Acceptance intimation: 25th March, 2010
* Camera ready copy due: 5th April, 2010
* Registration details announcement: 1st February, 2010
Instructions
* Presentations must report original work carried out by the authors.
* Presenters would be given a maximum of 30 minutes for their presentation.
* All participants must register for the workshop.
* Presentation may be submitted via: csi.sigai@gmail.com This e- mail address is being protected from spambots. You need JavaScript enabled to view it
ERTAI Secretariat
Centre for Development of Advanced Computing (Formerly NCST)
Raintree Marg, Near Bharati Vidyapeeth, Sector 7, CBD Belapur
Opp. Kharghar Railway Station, Navi Mumbai 400 614, Maharashtra, INDIA
Telephone: +91-22-27565303
Fax: +91-22-27565004 (on request)
Email: csi.sigai@gmail.com
Web: http://sigai.cdacmumbai.in/ -
Finding the nearest in a sorted set of int to a given int
Date: 12/05/09 Keywords: software, java
Hi guys,
I'm in the middle of writing a connector to some accounting software and I've been implementing a lazy loading list of proxies because I'm dealing with huge lists of items which load slowly (even the item id s load slowly).
That's not important to the question I am asking though, basically, I want an algorithm which finds either the given search int in my sorted set (of indexes) or the nearest int contained in the list (it doesn't matter, but we can say that the algorithm has a preference for lower numbers if 2 values are equally near)
The essence of the problem is outlined here:
import java.util.TreeSet;
public class Search {
static TreeSetsorted = new TreeSet ();
public static void main(String...args){
sorted.add(1);
sorted.add(3);
sorted.add(5);
sorted.add(7);
sorted.add(10);
findNearest(2); // return 1
findNearest(8); // return 7
findNearest(10); // return 10
}
private static Integer findNearest(Integer search) {
return null; //TODO halp pls!
}
}
Thanks for any advice in advance! -
Finding the nearest in a sorted set of int to a given int
Date: 12/05/09 Keywords: software, java
Hi guys,
I'm in the middle of writing a connector to some accounting software and I've been implementing a lazy loading list of proxies because I'm dealing with huge lists of items which load slowly (even the item id s load slowly).
That's not important to the question I am asking though, basically, I want an algorithm which finds either the given search int in my sorted set (of indexes) or the nearest int contained in the list (it doesn't matter, but we can say that the algorithm has a preference for lower numbers if 2 values are equally near)
The essence of the problem is outlined here:
import java.util.TreeSet;
public class Search {
static TreeSetsorted = new TreeSet ();
public static void main(String...args){
sorted.add(1);
sorted.add(3);
sorted.add(5);
sorted.add(7);
sorted.add(10);
findNearest(2); // return 1
findNearest(8); // return 7
findNearest(10); // return 10
}
private static Integer findNearest(Integer search) {
return null; //TODO halp pls!
}
}
Thanks for any advice in advance! -
Big-O for other parameters?
Date: 05/21/09 Keywords: no keywords
Is Big-O (and Omega and Theta) ever used for other algorithm cost parameters besides time? Like, could I usefully describe different presentation methodologies in terms of bandwidth consumption per n bytes of content as O (n log n) for example? Or is there a separate notation?
-
Big-O for other parameters?
Date: 05/21/09 Keywords: no keywords
Is Big-O (and Omega and Theta) ever used for other algorithm cost parameters besides time? Like, could I usefully describe different presentation methodologies in terms of bandwidth consumption per n bytes of content as O (n log n) for example? Or is there a separate notation?
-
n-th order statistics of the immutable data
Date: 03/04/09 Keywords: no keywords
what's the best asymptotic time complexity for a n-th order statistics algorithm on the immutable array of size N with memory consumption less then or equal to O(log N)? median of medians algorithm gives O(N) time complexity in the worst case, but I'm not sure about it's memory boundaries for the r/o array
UPD: anyway, it would be much interesting too for the case of the memory consumption less then or equal to O(sqrt N); or even O(K * N) where 0 < K << 1Source: http://community.livejournal.com/algorithms/101906.html
-
n-th order statistics of the immutable data
Date: 03/04/09 Keywords: no keywords
what's the best asymptotic time complexity for a n-th order statistics algorithm on the immutable array of size N with memory consumption less then or equal to O(log N)? median of medians algorithm gives O(N) time complexity in the worst case, but I'm not sure about it's memory boundaries for the r/o array
UPD: anyway, it would be much interesting too for the case of the memory consumption less then or equal to O(sqrt N); or even O(K * N) where 0 < K << 1 -
n-th order statistics of the immutable data
Date: 03/04/09 Keywords: no keywords
what's the best asymptotic time complexity for a n-th order statistics algorithm on the immutable array of size N with memory consumption less then or equal to O(log N)? median of medians algorithm gives O(N) time complexity in the worst case, but I'm not sure about it's memory boundaries for the r/o array
UPD: anyway, it would be much interesting too for the case of the memory consumption less then or equal to O(sqrt N); or even O(K * N) where 0 < K << 1 -
Partially sorted array
Date: 02/08/09 Keywords: no keywords
Let's say you have an array, which is sorted, and then some small number of the elements become corrupt, so the array is not sorted anymore. Is there some efficient way to sort it again that doesn't involve resorting the whole array? (You may not necessarily know which elements are corrupt)
Source: http://community.livejournal.com/algorithms/101636.html
| || | Next page |